
In a recent blog we wrote about the important differences between mature AI and generative AI when it comes to applications in manufacturing.
A quick reminder: mature – or classical AI – is robust, stable, explainable and fixable and at this point in their development classical AI models are pretty much deterministic. In other words, if the model says a product is defective, it is defective and if the model tells you that you need to perform maintenance on pump 15 you better go ahead and do so.
But how about generative AI, i.e. large language models (LLMs) like ChatGPT? Sure, you can use gen AI to write your emails, summarize your meeting notes and create amazing images if you know how to prompt it properly. But is there an application for gen AI in manufacturing?
There most certainly is and one of the “killer apps”, we think, is knowledge retrieval.
The Large Language Model “Killer App”: Knowledge Retrieval
There is decades of knowledge and insights collected in various documents and databases in a modern manufacturing operation. Not just production data, but manuals, information about prior production issues, standard operating procedures, other historical data, etc. Typically, this information is difficult and time-consuming to find because information is spread out over many different documents.
Being able to access, query and use that information easily and quickly could boost productivity.
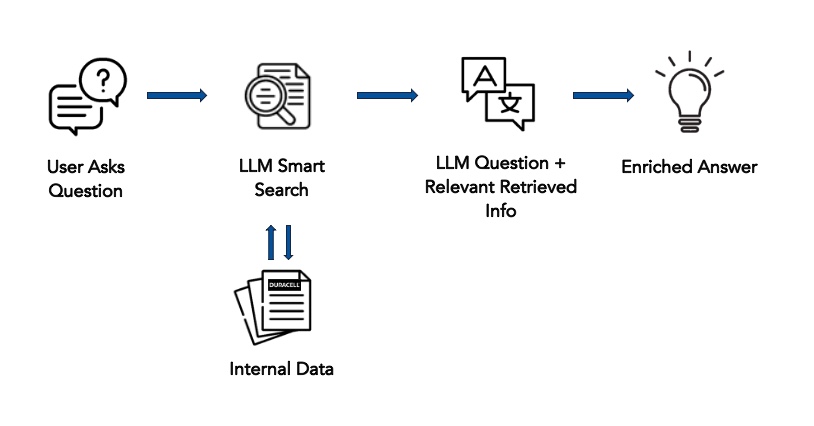
This is where large language models and a novel technique called RAG, or Retrieval-Augmented Generation, comes in. In short, RAG enhances the capabilities of large language models by combining the strengths of retrieval-based methods with generative models.
In laymen’s terms: you start with an existing trained LLM and provide additional training with your own documentation. This gives the model additional context and knowledge that wasn’t present in the original LLM training data. The model uses both the original input and the augmented information to generate precise answer to customer-specific questions like “Give me a step-by-step guide to replace part A.”, “How often have we seem defect x in the last three months?”
It can also create content, e.g. reports, that require specific knowledge by retrieving relevant references and including them in the generated text.
Sounds enticing?
We thought so, but before we go out to our customers and tell them to jump on that latest AI bandwagon, we had to check the process out for ourselves.
Augmenting a Large Language Model
In a first step we identified a highly specialized, somewhat unknown field outside of manufacturing with lots of available information to augment a large language model. The rationale for “highly specialized and somewhat unknown” is that we wanted to avoid that the existing LLM already knew a lot about the topic. Why? Because, if the LLM was already smart about the subject, it would be difficult to differentiate between knowledge the LLM already had and what it learned from ingesting our information. We settled for information unrelated to manufacturing because we simply didn’t have enough proprietary manufacturing information to meaningfully augment an existing model.
The subject we choose was carbon dioxide removal (CDR) from the atmosphere, a relatively new set of approaches aimed at drawing down CO2 already released into the atmosphere to counteract climate change. A little as 3 or 4 years ago, hardly any information was available on that topic but the published literature has since exploded.
This choice made sense because:
- While existing LLMs had a general notion of CDR, they did not have any depth or breadth of information.
- However, 1,000s of publications on all aspects of CDR have been published over the last few years giving us a large amount of data to augment the LLM.
- In the Open Air Collective we found a fantastic partner willing to dedicate time and expertise to this project.
- In Pulze AI we found a technology provider who was eager to support the project by giving us access to their platform, answering a myriad of questions and making adjustments as needed.
Using the Pulze AI platform we augmented existing LLMs with several hundred selected documents to create CDR.ai, the world’s first specialized large language model for CDR. We went through countless cycles of ingesting information and querying the LLMs to assess their answers, then ingesting more, querying again and so on. Finally, we beta-tested the model by giving early access to CDR experts and tasked them with asking hard questions and reporting any wrong answers or concerns.
To our delight, the augmented LLM performed very well and provided competent and correct answers.
If you are curious, you can give it a try here: CDR.ai.
Learnings from Augmenting a Large Language Model
Going through the process of augmenting a large language model taught us a thing or two. Here are the most important lessons we learned:
- Quality documentation is key. RAGs use what they ingest, if you feed them bad, biased, incomplete or outdated information, the answers will reflect that.
- Document availability is the crux. In the case of CDR.ai obtaining the documents was easy albeit time consuming. We limited the sources to high-quality scientific publications and reports (selected based on a set of strict quality criteria) from renowned institutes that we could download from the internet. Selecting which documents to include and collecting all the relevant documents in a manufacturing organization will be more involved and time consuming.
- Not all LLMs are created equal. Without getting too technical, the Pulze.AI platform allowed us to compare the answers from different standard LLMs (OpenAI, Mistral, LLama, Grok, etc) provided to the same question. In at least one case we found that one LLM gave the opposite (wrong) answer compare to all the others. Therefore, careful evaluation of what models are augmented and used is required and some models might need to be excluded.
- Ingestion doesn’t (yet) work for all types of documents: pdfs, word and text documents generally work well, complex figures and drawings, video and audio files are currently not possible. But things change quickly and most of these formats will likely be ingestible in the not-so-distant future.
- Augmented LLMs can be systematically prompted in a way that is not visible to the user. In the case of CDR.ai, users only get answers if their question is related to CDR. Somebody asking it about the meaning of life will receive a standard reply saying that it does not have enough information to answer the question. This feature will make the non-professional use of the model unattractive quickly.
- Experimentation and testing are crucial. This is still a new technology and it’s important to a) make sure the LLM provides solid answers and b) the user trusts the LLM to provide solid answers. “Playing” with model is the best way to be convinced of its performance.
- It is important to choose a platform that provides references to the documents it gleans the information from along with the answers. This is a useful in case there are any questions about the correctness of the answer: the user can simply click on the reference and verify the information.
- Good project management practices apply, it’s important to sort out use cases, user requirement, maintenance procedures, revision control, recovery procedures etc before augmentation begins in earnest, documentation such as FAQs and user training are required to make the newly augmented LLM a useful tool.
Augmenting large language models with highly specific information worked extremely well in our hands and the answers our augmented large language model provides are comprehensive, overwhelmingly correct, verifiable and impressive.
It’s time to implement it in manufacturing!
Want to give it a try? Let us know.